In the modern era, machine learning (ML) has become a game-changing tool for many industries. Among them, the retail industry is harnessing the power of ML to analyze consumer behavior, optimize inventory, predict trends, and enhance customer experiences. In this blog, we’ll explore the process of building a basic machine learning model, applying it in the context of retail data analysis, and providing a use case that demonstrates how you can extract business insights from predictive models.
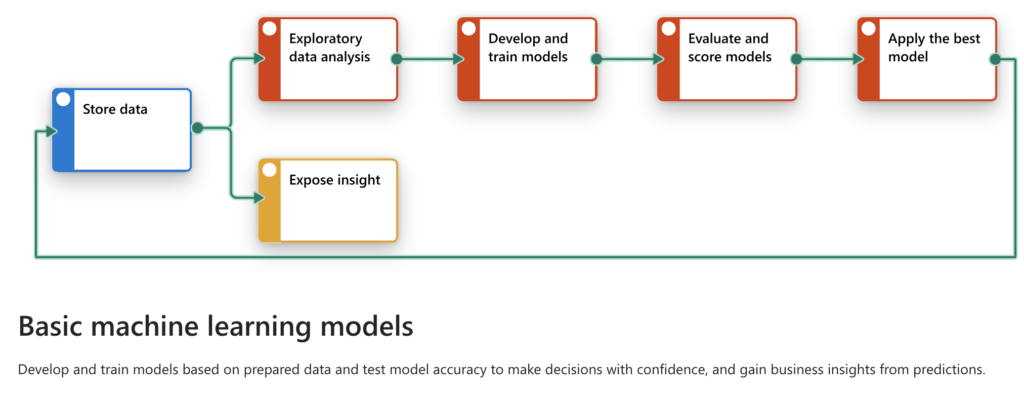
Understanding the Basic ML Pipeline Stages
A machine learning project generally consists of several distinct stages, as illustrated in the images provided. The stages include:
- Store Data: Collecting and organizing data for the analysis.
- This stage is represented by the blue box labeled “Store data” in the provided diagram.
- Exploratory Data Analysis (EDA): Understanding the data through visualization and statistical summaries.
- The red box labeled “Exploratory data analysis” represents this step, where data trends are analyzed to gain insights before building a model.
- Develop and Train Models: Creating machine learning models using different algorithms to extract patterns.
- This stage is shown in the red box labeled “Develop and train models” where various algorithms are used to identify relationships in the data.
- Evaluate and Score Models: Testing the accuracy and reliability of the developed models.
- Represented by the red box labeled “Evaluate and score models”, the models are validated for accuracy to determine the best one.
- Apply the Best Model: Deploying the model that gives the best performance to generate predictions.
- The red box labeled “Apply the best model” indicates that the optimal model is selected and used for prediction tasks.
- Expose Insights: Sharing the insights extracted from the model to support decision-making.
- The yellow box labeled “Expose insight” represents the final step where actionable insights are communicated to stakeholders.
This end-to-end pipeline is foundational for any machine learning solution and allows for structured development and deployment of predictive models.
Required Workloads and Item Types
To execute such a machine learning project effectively, several technologies and tools are required:
- Data Engineering: Building and managing the data infrastructure, using tools like Azure Data Lakehouse or AWS S3 to store and organize data.
- Data Science: Developing machine learning models using tools like Jupyter Notebook and Python libraries such as Pandas, NumPy, and Scikit-learn.
- Power BI: For data visualization and generating reports that provide meaningful insights.
Specific items needed in this pipeline include:

- Lakehouse: A centralised repository for storing structured and unstructured data.
- Notebook: A working environment for executing code for data analysis, training, and evaluation.
- ML Model: The mathematical representation that learns from the data to make predictions.
- Experiment: Testing and optimizing different ML models.
- Environment: A controlled space to ensure that dependencies and versions of tools are consistent throughout the project lifecycle.
- Report: A summarized view of model performance and insights gained, typically for business stakeholders.
The second image lists the required workloads and item types, such as Data Engineering, Data Science, and Power BI for handling data and generating insights, as well as items like Lakehouse, Notebook, Experiment, Environment, and Report for facilitating the pipeline stages.
Building an ML Model for Retail Data Analysis
Let’s explore the steps involved in a practical use case, focusing on how a retail company can use ML to predict product demand and improve inventory management.
Step 1: Store Data
The first step is collecting and storing data. Retail data typically includes sales data, customer demographics, product catalogs, and historical transaction data. This data can be collected in a Lakehouse such as Azure Synapse or Amazon Redshift for a unified view of all available data.
Step 2: Exploratory Data Analysis
Exploratory Data Analysis (EDA) helps in gaining an initial understanding of the data. Key activities include:
- Handling Missing Values: Ensuring there are no gaps in the data, using techniques like imputation.
- Visualizing Trends: Using tools like Power BI or Matplotlib in Python to create visualizations that show purchasing trends over time.
- Identifying Outliers: Removing data points that might skew the results, such as unrealistically high product demand during one-off events.
Step 3: Develop and Train Models
Once EDA is complete, the next step is to develop models that can predict customer behavior and product demand. A typical approach might include:
- Choosing the Algorithm: For retail data, models like Linear Regression for demand forecasting or Random Forest for classification tasks (e.g., customer segmentation) are often used.
- Training the Model: Using historical sales data, the model is trained to understand the relationship between input features (like time of year, discounts, customer demographics) and output labels (like product sales).
Step 4: Evaluate and Score Models
The next step is to evaluate the models using metrics like Mean Absolute Error (MAE) or Root Mean Square Error (RMSE) for regression tasks. The goal is to select the model that offers the best trade-off between complexity and accuracy.
- Cross-Validation: Dividing the data into multiple subsets to validate the model’s performance across different partitions.
- Scoring: Assigning scores to models to understand how they perform on new data.
Step 5: Apply the Best Model
The model that has the highest evaluation score is selected and applied to real-world data. For example, if a retailer wants to optimize inventory, the demand forecasting model can help predict how much of each product to keep in stock.
- Deployment: This can be done using cloud services like Azure Machine Learning or AWS SageMaker to make the model accessible for ongoing predictions.
Step 6: Expose Insights
Finally, the predictions made by the model need to be presented to stakeholders in an understandable format. This is typically done by creating Power BI dashboards or other visual reports that summarize the key insights.
- Actionable Insights: For instance, the model’s output might show that demand for a particular product is expected to rise significantly during the holiday season. This insight can be used to adjust inventory and prevent stockouts.
Use Case: Improving Inventory Management in Retail
Scenario
Consider a retail chain that sells clothing and accessories. The store manager needs to ensure they always have enough stock to meet demand without overstocking. To achieve this, they collect sales data for all items, including timestamps, product IDs, customer data, price, and promotional offers.
Data Preparation
The data is stored in an Azure Data Lake and is cleaned through a series of Azure Data Factory pipelines. Missing values are filled using median imputation, and outliers are removed after visual inspection.
Model Development
A Random Forest Regressor model is chosen for demand prediction because of its flexibility and ability to handle non-linear relationships. The model is trained using features like seasonality, promotions, pricing, and customer demographics.
Model Deployment and Insights
The trained model is deployed in Azure ML for real-time predictions. Power BI is used to visualize the model’s predictions, and the results are shared with stakeholders through an interactive dashboard. The insights include:
- Seasonal Trends: Higher demand for accessories during the summer.
- Price Sensitivity: Sales increase by 15% when a 10% discount is applied.
These insights help the retail chain maintain optimal inventory levels, minimizing the risk of overstocking while ensuring customer satisfaction.
Tools and Technologies
For this project, the following tools were used:
- Azure Data Lake: To store and manage data.
- Jupyter Notebooks in Azure ML Studio: For model development.
- Scikit-Learn: To build and train the Random Forest Regressor model.
- Azure ML Service: For deploying the model as a web service.
- Power BI: To visualize predictions and share insights.
Conclusion
Building a machine learning model for the retail industry involves multiple stages—from data collection and cleaning to model deployment and visualization. A well-defined ML pipeline helps businesses extract actionable insights, optimize decision-making processes, and boost profitability.
In our use case, we demonstrated how to predict product demand and optimize inventory management, thereby reducing costs and improving customer satisfaction.