Data is the new oil, and managing it efficiently requires robust architectures that can handle multiple data streams in real time as well as in batches. One such hybrid approach is Lambda Architecture, which allows organizations to analyze both batch and real-time data in a single system while keeping these two processes separate but integrated. In this blog, we will explore the Lambda architecture, its required workloads, item types, and use case scenarios that illustrate its power in data engineering and machine learning.
Required Workloads and Item Types for Lambda Architecture
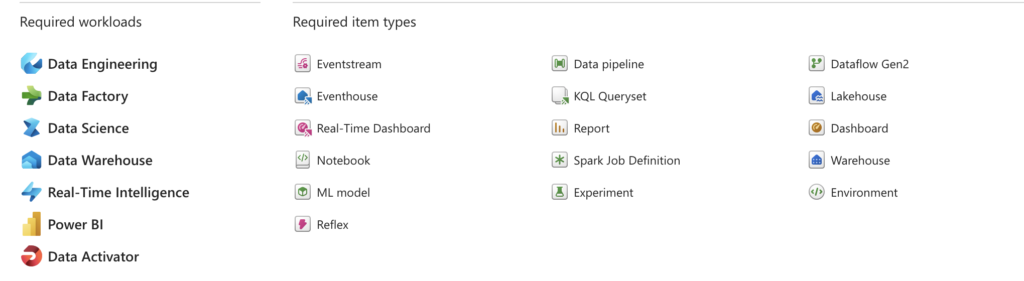
In order to effectively implement Lambda architecture, several workloads and item types are required. These include:
1. Required Workloads:
- Data Engineering: Core engineering activities such as data ingestion, transformation, and structuring are needed to ensure the data can be processed.
- Data Factory: The ability to create and orchestrate pipelines is crucial for moving data across different layers of the architecture.
- Data Science: For experimentation, training machine learning models, and building predictive capabilities.
- Data Warehouse: A structured data storage solution that allows analytics on massive volumes of data.
- Real-Time Intelligence: Managing and analyzing real-time data streams is a critical aspect of the Lambda architecture.
- Power BI: Visualization and reporting are key to making sense of the data.
- Data Activator: Real-time decision-making based on analyzed data.
2. Required Item Types:
- Eventstream: Real-time data streaming, allowing for continuous data flow from sources like IoT sensors or user activity.
- Eventhouse: A repository for raw event data before it’s processed.
- Real-Time Dashboard: Visual representation of the processed streaming data for real-time decision-making.
- Data Pipeline: Manages batch data processing and movement from various sources.
- ML Model: Machine learning model creation and integration.
- Spark Job Definition: Defining and running batch jobs for processing large datasets.
- Dataflow Gen2: Manages data transformations and analytics within a cloud environment.
- Lakehouse: A combination of a data warehouse and data lake for structured and unstructured data.
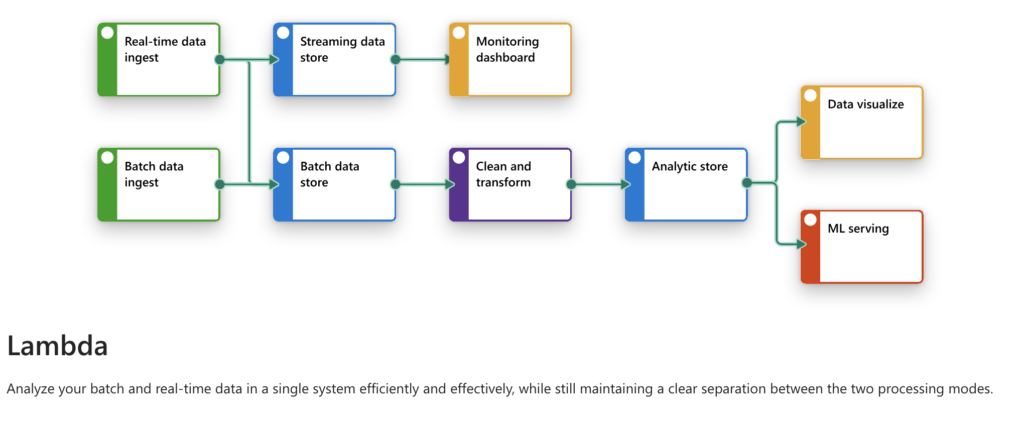
The Lambda Architecture Design Pattern
Lambda Architecture works by processing both real-time and batch data in a single integrated system. Below is a flow of how Lambda works:
- Real-time Data Ingest & Batch Data Ingest:
- Real-Time Data Ingest: Used for streaming data, often coming from IoT devices, logs, or external APIs, requiring immediate transformation.
- Batch Data Ingest: Pulls data at periodic intervals to ensure completeness and accuracy, often used for historical data.
- Streaming Data Store & Batch Data Store:
- The real-time and batch data ingestions are stored separately; the real-time data goes to a streaming data store, and the batch data goes to a separate storage for further processing.
- Clean and Transform:
- This stage applies data transformations to clean the data for analytics and use cases downstream.
- Analytic Store:
- The cleaned data is then moved to an analytics store where it can be accessed for real-time analysis or historical data insights.
- Monitoring Dashboard, Data Visualization, ML Serving:
- A monitoring dashboard is created to provide visibility into data streams.
- Visualizations like reports and dashboards allow stakeholders to easily grasp data insights.
- ML Serving delivers the results of machine learning models in real-time, enhancing decision-making capabilities.
Use Case: Monitoring and Predicting Energy Consumption
Imagine a utility company that wants to monitor energy consumption in real-time across multiple regions, while also predicting future consumption based on historical data. Here’s how Lambda architecture fits in:
Real-Time Monitoring: Using smart meters across homes, the data is streamed to the system using Eventstream. This data is stored in a Streaming Data Store, which is then processed by a real-time processing layer to create a Real-Time Dashboard that shows current energy usage, peak times, and areas with high usage.
Batch Processing: Historical data from the past years is ingested as Batch Data. This data goes into a Batch Data Store where it undergoes cleaning and transformations to make it useful for analysis.
Data Pipeline & Lakehouse: The batch data moves through Data Pipelines and is stored in a Lakehouse, combining the benefits of a data lake and a warehouse. It provides flexibility to store both structured and unstructured data.
Machine Learning and Predictions: Using ML Models developed through the Data Science workload, the cleaned batch data is used to train the models that predict future consumption. The predictions are then fed into a Monitoring Dashboard or used by an automated system that adjusts energy production.
Reflex & Dataflow: The system uses Dataflow Gen2 to manage the integration between real-time streams and batch layers, ensuring data consistency. Reflex is used for making real-time adjustments and activating data-driven actions to balance the energy supply.
Advantages of Lambda Architecture
Real-Time Decision Making: By combining batch and real-time data, organizations can make instant decisions without losing the insight gained from historical data.
Fault Tolerance: Since Lambda maintains both batch and real-time data paths, the data is more resilient in case one system fails.
Scalable Analytics: Batch processing and data warehousing capabilities provide a robust platform for large-scale analytics and machine learning.
Challenges with Lambda Architecture
Complexity: It requires maintaining two different layers (real-time and batch), which increases the complexity of the system.
Consistency: Ensuring consistency between batch and real-time layers can be challenging, as it may require running reconciliations frequently.
Conclusion
Lambda architecture presents a unique solution for businesses that need to have the best of both real-time and historical data processing capabilities. The separation between real-time and batch processes allows for efficient and consistent data handling, providing end-to-end data visibility and fast responses, which is crucial for modern businesses looking to stay competitive.
The use of a combination of tools and workloads, as illustrated above, makes Lambda architecture a go-to solution for building resilient, scalable, and efficient data pipelines for diverse industries like energy, healthcare, and finance. For those looking to leverage real-time intelligence and long-term data analytics, Lambda offers a perfect balance that can drive real-time decisions while preserving insights from historical data.