Amazon Elastic MapReduce (EMR) is a popular AWS service for big data processing, offering a managed environment to run large-scale distributed data processing frameworks like Apache Spark, Hadoop, and others. EMR Studio is a web-based integrated development environment (IDE) that allows you to develop, visualize, and debug big data applications. Recently, AWS introduced EMR Serverless, a new option that simplifies the way you manage and run big data workloads by removing the need to manage clusters or EC2 instances. It supports both batch and streaming jobs, making it a flexible solution for a variety of data processing tasks.
In this blog, we will cover how to create and manage applications using EMR Studio and EMR Serverless, along with a step-by-step guide to setting up your first EMR Serverless application, optimized for either batch or streaming jobs.
What is EMR Studio?
AWS EMR Studio provides a collaborative, fully managed development environment tailored for big data workloads on AWS. It allows users to build, monitor, and debug applications using popular frameworks like Apache Spark. EMR Studio integrates deeply with other AWS services such as Amazon Athena, AWS Glue, and Amazon SageMaker to provide a seamless experience for data analytics and machine learning workflows.
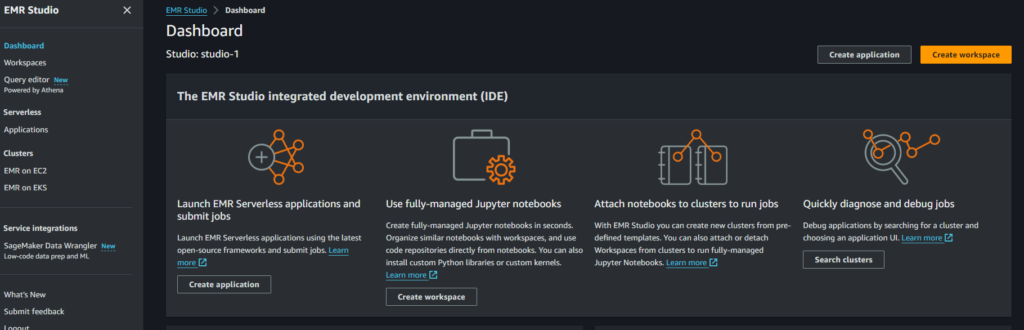
Key features of EMR Studio include:
- Query Editor: For running queries against data using SQL.
- Workspaces: Organize notebooks and scripts into workspaces.
- Applications: Manage and run data processing applications using frameworks like Apache Spark and Hive.
- Serverless Processing: With EMR Serverless, users no longer need to provision and manage underlying infrastructure (clusters) to run applications.
What is EMR Serverless?
EMR Serverless is a serverless option for running big data jobs without needing to provision, configure, or manage clusters. With EMR Serverless, you submit jobs to an application, and AWS handles the scaling, deployment, and management of resources. It is especially useful for streaming jobs and batch processing. It supports real-time data processing from sources like Apache Kafka and Amazon Kinesis Data Streams, making it ideal for near real-time analytics.
Key Features of EMR Serverless:
- Stream and Batch Processing: Supports both batch and streaming jobs, allowing flexibility in processing real-time and historical data.
- Automatic Scaling: Dynamically adjusts resources (CPU, memory, disk) based on the workload.
- Simplified Infrastructure: No need to manage clusters, instances, or auto-scaling groups.
- Cost Efficiency: You only pay for the resources your jobs consume during execution.
- Integration with AWS Glue: EMR Serverless can use AWS Glue Data Catalog as a metastore for managing table metadata.
Step-by-Step Guide: Creating an EMR Serverless Application
Here, we’ll walk you through the process of creating and managing your first EMR Serverless application through the EMR Studio interface.
Step 1: Navigate to EMR Studio
- From your AWS Management Console, go to EMR Studio.
- You’ll see a dashboard with options for creating and managing applications, workspaces, and query editors.
- Click on Applications to start the process of creating a new EMR Serverless application.
Step 2: Create a New Application
- Click on Create Application. You will be presented with a form to set up the details of your application.
Application Settings:
- Name: Give your application a unique name, such as “My_First_Application”. The name can include up to 64 alphanumeric characters, underscores, hyphens, and periods.
- Type: Choose the type of application. For this guide, we’ll select Spark, but other frameworks like Hive are also available.
- Release Version: Choose the EMR release version. A typical choice is emr-7.2.0 which includes the latest stable Spark release.
Step 3: Choose Architecture
AWS EMR supports two architecture options:
- x86_64: This option uses traditional x86 processors and is compatible with most third-party libraries and tools.
- arm64 (Graviton): This option uses AWS Graviton processors, offering better performance at a lower cost. Note that you may need to recompile some libraries if you choose this option.
Select x86_64 for compatibility unless you are optimizing for cost and are familiar with Graviton.
Step 4: Configure Application Setup Options
Next, you’ll choose how the application will be set up and run:
- Use Default Settings: Choose this option if you’re setting up a simple batch job or interactive workload. It pre-configures the job to use default settings.
- Use Custom Settings: If you require more control, such as defining network connections, pre-initialized capacity, or custom images, you can use this option.
For simplicity, select Use Default Settings for Batch Jobs Only.
Application Limits:
- Set the maximum resources your application can consume, such as 400 vCPUs, 3000 GB memory, and 20000 GB disk. These limits help prevent runaway jobs from consuming too many resources.
Step 5: Enable Interactive Endpoint (Optional)
Interactive workloads can be run using Apache Livy endpoints. If you need to submit interactive workloads via a notebook or run commands interactively from EMR Studio, enable this option.
For now, you can leave this disabled if you’re focusing on batch jobs.
Step 6: Configure the Metastore and Logging
- Metastore Configuration: Enable AWS Glue Data Catalog to use AWS Glue as your metastore. This ensures your application can use the shared metadata across your data lake.
- Application Logs: By default, AWS DMS stores logs in AWS-managed storage. Ensure this is enabled for monitoring and debugging purposes.
Step 7: Auto Start and Stop Application
You can configure the application behavior when a job is submitted:
- Auto Start: Automatically starts the application when you submit a job.
- Auto Stop: Automatically stops the application after it has been idle for 15 minutes. This is useful for cost savings, as you won’t be charged for idle time.
Step 8: Submit Application
Once everything is configured, click Create and Start Application to submit the application. AWS will automatically start the resources required for your EMR Serverless application.
EMR Serverless: Streaming Jobs for Near Real-Time Data Processing
With the introduction of streaming jobs, EMR Serverless now supports stream processing, allowing you to process data in near real-time from sources such as Apache Kafka and Amazon Kinesis Data Streams. Streaming jobs are optimized for continuous data processing, making them ideal for use cases like log aggregation, real-time analytics, and fraud detection.
Here’s how streaming jobs work:
- Data Sources: Stream data is continuously ingested from services like Amazon Kinesis or Apache Kafka.
- Processing: Streaming jobs use frameworks such as Apache Spark’s Structured Streaming to process data in near real-time.
- Output: Results can be written to AWS services like Amazon S3, DynamoDB, or RDS for further processing or storage.
Conclusion
AWS EMR Studio and EMR Serverless offer powerful solutions for running big data workloads with minimal management overhead. EMR Studio provides a robust environment for developing, running, and monitoring applications, while EMR Serverless removes the need to manage clusters, making it easy to run batch and streaming jobs.
Whether you’re processing large-scale data with Apache Spark or handling real-time streaming data from Kafka or Kinesis, EMR Serverless provides the scalability and flexibility to handle a wide variety of use cases.
Key Takeaways:
- EMR Studio offers a collaborative environment for developing big data applications.
- EMR Serverless allows you to run data processing jobs without the need to manage clusters.
- Streaming Jobs in EMR Serverless let you process real-time data from sources like Apache Kafka and Amazon Kinesis with ease.