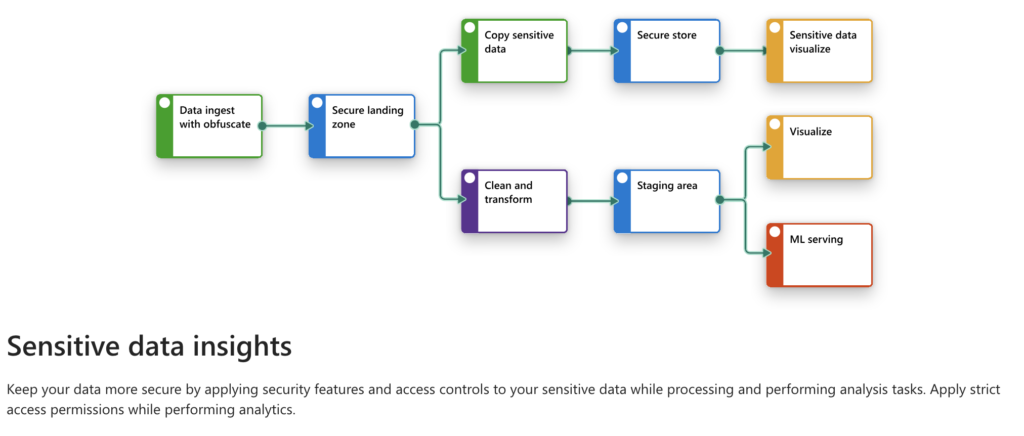
In the pharmaceutical industry, managing and processing data is a highly regulated and complex process. From clinical trial management to drug discovery, the data lifecycle must adhere to stringent security and privacy requirements. With sensitive patient health information (PHI) involved, data must be securely ingested, processed, analyzed, and visualized. In this blog post, I’ll walk through the architecture and implementation of a secure data pipeline designed specifically for clinical trials, showcasing how a modern cloud-based stack like Azure, Databricks, and Power BI can be leveraged for such workflows.
Key Challenges in Pharmaceutical Data Processing
Sensitive Data: Handling PHI introduces complexities, including strict compliance with regulations like GDPR and HIPAA.
Data Privacy and Security: Ensuring that only authorized personnel can access data while keeping it encrypted and obfuscated.
Scalability: Clinical trials can involve thousands of patients across multiple regions, generating large volumes of data. Scalability becomes a key consideration.
Data Integration: Data is collected from different sources, including hospitals, labs, and clinical trial sites, which needs to be integrated seamlessly.
Machine Learning: Applying machine learning (ML) models to large datasets for insights like adverse event prediction or trial optimization.
The Data Pipeline Architecture
Let’s explore the data pipeline and how it addresses these challenges.
1. Data Ingestion with Obfuscation
The first step in the pipeline involves ingesting raw data from multiple clinical trial sites. Data ingestion must account for the sensitive nature of patient information by applying obfuscation techniques.
Key Technologies:
Azure Data Factory: Used for ingesting data from hospitals, clinical trial sites, and laboratory databases.
Obfuscation Tooling: Custom scripts or Azure Purview can be employed to obfuscate patient identifiers (e.g., names, addresses) while maintaining the integrity of other critical trial data.
Security Consideration:
Apply obfuscation early in the ingestion process, ensuring that PHI is never directly exposed in the pipeline.
Role-based access control (RBAC) ensures that only authorized users can access raw or obfuscated data.
2. Secure Landing Zone
After obfuscation, the data is moved to a Secure Landing Zone, which is an encrypted storage space for raw trial data before any processing or transformation begins.
Key Technologies:
Azure Data Lake Storage (ADLS): For encrypted and secure raw data storage.
AWS S3 (if using AWS cloud): Secure bucket with server-side encryption using AWS Key Management Service (KMS).
Security Consideration:
Ensure encryption at rest and in transit.
Implement network security rules to allow only certain IP ranges or subnets to access the data.
3. Data Transformation and Cleaning
Clinical data often contains missing values, duplicates, or inconsistencies that need to be cleaned and transformed for further processing. At this stage, machine learning-ready datasets are created by handling null values, outliers, and applying necessary transformations.
Key Technologies:
Databricks: Ideal for scalable data processing and transformation. Using PySpark, we can efficiently clean and normalize the clinical trial data.
Azure Synapse Analytics: For large-scale data analytics and transformation.
Example Transformation Tasks:
Handling missing values: Apply imputation techniques to fill missing data points.
Outlier detection: Use statistical methods or machine learning models to detect and flag outliers for review.
Security Consideration:
Limit access to sensitive datasets with token-based access.
Databricks Secrets: Use secrets management for credentials and sensitive connection strings.
4. Secure Storage
After transformation, the data is stored securely for further analysis, machine learning, and visualization. This storage is crucial for both compliance and auditing, as clinical trial data must often be preserved for extended periods.
Key Technologies:
Azure Blob Storage or AWS S3: For secure, scalable storage of processed clinical trial data.
Version Control: Store data in a versioned format to maintain data lineage and track changes over time.
5. Data Visualization and Reporting
The transformed data is then visualized for both internal stakeholders (researchers, doctors) and regulatory bodies. However, sensitive data must still be protected during visualization to comply with regulations.
Key Technologies:
Power BI: For creating secure, interactive dashboards that visualize clinical trial progress, patient outcomes, and adverse events.
Tableau or Amazon QuickSight: Alternatively, can be used to visualize trial data.
Security Consideration:
Ensure that sensitive data is masked in visualizations, using Power BI’s Row-Level Security (RLS) or similar techniques.
Audit all data access to ensure that only authorized users can view sensitive metrics.
6. Machine Learning Serving
Once data is cleaned, transformed, and securely stored, it is time to apply machine learning models. In clinical trials, ML models can help predict drug efficacy, optimal dosage levels, and potential adverse reactions based on historical data.
Key Technologies:
Databricks ML: For developing, training, and deploying ML models at scale. Databricks integrates seamlessly with Azure Machine Learning and other services for training complex models.
Azure Machine Learning: Alternatively, Azure’s ML service can be used for model development and deployment.
Sample ML Use Cases:
Adverse Event Prediction: Predict the likelihood of adverse events in specific demographics using historical data from past clinical trials.
Optimal Dosage Calculation: Use ML models to analyze dosage levels across patient populations and predict the most effective and safest doses.
Security Consideration:
Apply data anonymization techniques before feeding the data into machine learning models to protect sensitive patient information.
7. Post-Trial Reporting and Data Compliance
Once the clinical trial is complete, pharmaceutical companies must submit reports to regulatory bodies. These reports include sensitive patient data that needs to be stored and shared securely.
Key Technologies:
Azure Purview: For managing sensitive data across the lifecycle and ensuring compliance with regulatory requirements.
Azure Key Vault or AWS KMS: For managing encryption keys and securing sensitive information during report generation.
How This Pipeline Ensures Data Security and Compliance
The pharmaceutical industry is governed by regulations like GDPR in Europe and HIPAA in the United States. Non-compliance with these regulations can result in hefty fines, making data security a top priority. Here’s how this pipeline ensures compliance:
Data Obfuscation: By obfuscating patient identifiers at the point of ingestion, the pipeline ensures that sensitive data is protected even before it enters the cloud.
Encryption at Rest and In Transit: All data stored in the pipeline is encrypted using industry-standard encryption algorithms, both while at rest and during transit between stages.
Role-Based Access Control: Only authorized personnel have access to sensitive data, with access controls implemented at every stage of the pipeline.
Compliance Auditing: Azure and AWS services provide detailed logging and auditing features to ensure that all data access is tracked and compliant with regulatory requirements.
Data Anonymization for ML: Machine learning models are trained on anonymized data, ensuring that sensitive PHI is never exposed during model development or serving.
Conclusion
The pharmaceutical industry can leverage modern cloud data pipelines to streamline clinical trials while ensuring data security and regulatory compliance. By integrating tools like Azure Data Factory, Databricks, Power BI, and secure cloud storage, pharmaceutical companies can efficiently handle large volumes of clinical data while protecting sensitive patient information.
Building such a secure and scalable data pipeline allows companies to accelerate drug discovery, improve patient outcomes, and stay compliant with global data privacy regulations.